
pwn入门
初级工具列表
参考文章Ubuntu下pwn环境搭建
windows下安装IDA pro
Linux (ubuntu,kali等发行版) 或使用WSL (Windows Subsystem for Linux),建议使用ubuntu22.04 (因为我用的这个版本,出了问题方便排查,这个版本只有python3没有python2)
(安装完系统先执行以下两条命令)
1sudo apt update2sudo apt upgrade(若无pip,则先安装pip) sudo apt install python3-pip
安装pwntools sudo pip install pwntools
安装GDB sudo apt install gdb
安装pwndbg
1git clone https://github.com/pwndbg/pwndbg2cd pwndbg3./setup.sh安装ROPgadget
1sudo apt-get install python-capstone2git clone https://github.com/JonathanSalwan/ROPgadget.git3cd ROPgadget4sudo python3 setup.py install(可选)安装zsh和oh-my-zsh,详见请点击,个人认为zsh比bash好用
初级应该就这些,后续教学中会再补充
汇编基础
参考文章Pwn入门系列1——汇编语言基础
必备量词
| 代码 | 含义 | 字节数 |
|---|---|---|
| bit | 比特 | 1位 |
| byte | 字节 | 8位 |
| word | 字 | 16位 |
| dword | 双字 | 32位 |
| qword | 四字 | 64位 |
机器码
- 深入底层后,计算机其实很笨,只能完成一些很基本的操作,但是速度很快。
- 机器码就是一个个0和1组成的,为了方便人类的阅读,一般都以16进制呈现。
- 尽管如此,一个个16进制字符可读性仍然很差
- 汇编语言就是把这些及其指令代码以助记符的形式翻译一下,方便人类的阅读。
寄存器
- 计算机的指令都是由CPU来执行
- 在计算机系统结构中,CPU和内存是分开的。
- 寄存器存在于CPU中,是CPU的直接操作对象。
| 寄存器名称 | 作用 | 备注 |
|---|---|---|
| RAX | 通用寄存器 | 低32位:EAX ; 低16位:AX; 高8位:AH; 低8位:AL |
| RBX | 通用寄存器 | 同上 |
| RCX | 通用寄存器 | 同上 |
| RDX | 通用寄存器 | 同上 |
| RDI | 通用寄存器 | 低32位:EDI |
| RSI | 通用寄存器 | 同上 |
| R8 | 通用寄存器 | 低32位:R8d; 低16位:R8W; 低8位:R8B |
| R9 | 通用寄存器 | 同上 |
| R10 | 通用寄存器 | 同上 |
| R11 | 通用寄存器 | 同上 |
| R12 | 通用寄存器 | 同上 |
| R13 | 通用寄存器 | 同上 |
| R14 | 通用寄存器 | 同上 |
| R15 | 通用寄存器 | 同上 |
- 上述的通用寄存器,通常用于参数传递以及算数运算等通用场合
- RSP为栈顶指针,RBP为栈底指针,二者用于维护程序运行时的函数栈
- EFLAGS为标志位寄存器,用于存储CPU运行时计算过程中的状态,如进位溢出等。
- RIP指针用于存储CPU下一条将会执行的指针,不能直接修改,正常情况下会每一次运行一条指令自增一条指令的长度,当发生跳转时才会以其他形式改变其值。
寻址方式
| 寻址方式 | 示例 | 实际访问 |
|---|---|---|
| 立即寻址 | 1234h | 1234h这个数字本身 |
| 直接寻址 | [1234h] | 内存地址1234h |
| 寄存器寻址 | RAX | 访问RAX寄存器 |
| 寄存器间接寻址 | [RAX] | 访问RAX寄存器存储的值的这一内存地址 |
| 变址寻址 | [RAX+1234h] | 访问RAX寄存器存储的值+1234h这一内存地址 |
常见指令
| 指令类型 | 操作码 | 例子(intel格式) | 实际效果 | 备注 |
|---|---|---|---|---|
| 数据传送指令 | mov | mov rax,rbx | rax=rbx | |
| 取地址指令 | lea | lea rax,[rbx] | rax=&*rbx | 注:lea eax,[401000h] 将值401000h写入eax寄存器中,与mov eax,401000h等价 ; lea eax,c 其中c为一个int型的变量,该条语句的意思是把c的地址赋值给eax |
| 算数运算指令 | add | add rax,rbx | rax=rax+rbx | |
| | sub | sub rax,rbx | rax=rax-rbx | |
| 逻辑运算指令 | and | and rax,rbx | rax=rax&rbx | |
| | or | or rax,rbx | ` rax=rax | rbx` |
| | xor | xor rax,rbx | rax=rax^rbx | |
| | not | not rax | rax=~rax | |
| 函数调用指令 | call | call 1234h | 执行内存地址1234h处的函数 | |
| 函数返回指令 | ret | 函数返回 | ||
| 无条件跳转 | jmp | jmp 1234h | eip=1234h | |
| 栈操作指令 | push | push rax | 将rax存储的值压栈 | |
| | pop | pop rax | 将栈顶的值赋值给rax,rsp+=4(8) |
1CF(carry flag):进位标志 描述了最近操作是否发生了进位(可以检查无符号操作是否溢出)2
3ZF(zero flag):零标志 最近操作结果为0(列如 逻辑操作 等)4
5SF(sign flag):符号标志最近操作结果为负数6
7OF(overflow flag):溢出标志最近操作导致一个补码溢出 补码溢出通常有两种结果(正溢出或者负溢出)比较指令 cmp cmp 目标操作数,源操作数 用目标操作数减去源操作数,根据结果来确定溢出、符号、零、进位、辅助进位和奇偶标志位,但不会真的去改变目标操作数,仅改变了标志位。汇编的cmp指令相当于高级语言的IF语句。
比较两个无符号数
| CMP结果 | ZF | CF |
|---|---|---|
| 目的操作数 < 源操作数 | 0 | 1 |
| 目的操作数 > 源操作数 | 0 | 0 |
| 目的操作数 = 源操作数 | 1 | 0 |
比较两个有符号数
| CMP结果 | 标志位 |
|---|---|
| 目的操作数 < 源操作数 | SF ≠ OF |
| 目的操作数 > 源操作数 | SF=OF |
| 目的操作数 = 源操作数 | ZF=1 |
有条件跳转:
| 指令 | 解释 |
|---|---|
| jz | 如果ZF=1,跳转至指定位置 |
| jnz | 如果ZF=0,跳转至制定位置 |
| je | 与jz类似,但通常在一条cmp指令后使用。如果源操作数与目的操作数相等,则跳转 |
| jne | 与jnz类似,但通常在一条cmp指令后使用。如果源操作数与目的操作数不相等,则跳转 |
| jg | cmp指令做有符号比较之后,如果目的操作数大于原操作数,跳转 |
| jge | cmp指令做有符号比较之后,如果目的操作数大于或等于原操作数,跳转 |
| ja | 与jg类似,但使用无符号比较 |
| jae | 与jge类似,但使用无符号比较 |
| jl | cmp指令做有符号比较之后,如果目的操作数小于原操作数,则跳转 |
| jle | cmp指令做有符号比较之后,如果目的操作数小于或等于原操作数,则跳转 |
| jb | 与jl类似,但使用无符号比较 |
| jbe | 与jle类似,但使用无符号比较 |
| jo | 如果前一条指令置位了溢出标志位(OF=1),则跳转 |
| js | 如果符号标志位被置位(SF=1),则跳转 |
| jecxz | 如果ECX=0,则跳转 |
以上大部分仅仅了解,可以在实战中提升自己的汇编能力
架构解释
x86_64 == x64 == amd64
x86 == i386
编译原理

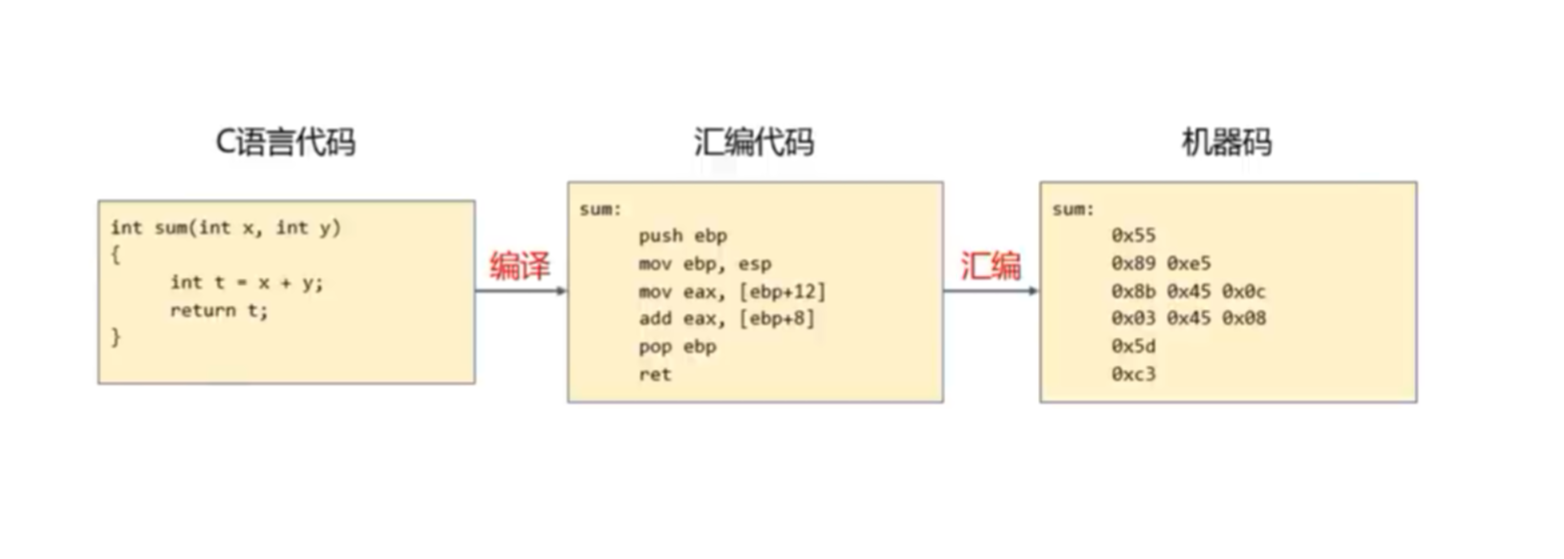
GCC编译C源代码有四个步骤:预处理—->编译—->汇编—->链接
以源程序hello.c为例
1#include <stdio.h>2
3int main()4{5 printf("happy new year!\n");6 return 0;7}预处理阶段(.c—.i) 编译器将C程序的头文件编译进来,还有宏的替换,可以用gcc的参数-E来参看。
命令:gcc –o hello hello.c 作用:将hello.c预处理输出hello.i
编译(.i—.s)转换为汇编语言文件 这个阶段编译器主要做词法分析、语法分析、语义分析等,在检查无错误后后,把代码翻译成汇编语言。可用gcc的参数-S来参看。 编译器(ccl)将文本文件hello.i 翻译成文本文件hello.s, 它包含一个汇编语言程序。 一条低级机器语言指令。 命令:gcc -S hello.i -o hello.s 作用:将预处理输出文件hello.i汇编成hello.s文件
汇编阶段(.s—.o)得到机器语言 汇编器as 将hello.s 翻译成机器语言保存在hello.o 中(二进制文本形式)。
链接阶段 printf函数存在于一个名为printf.o的单独预编译目标文件中。必须得将其并入到hello.o的程序中,链接器就是负责处理这两个的并入,结果得到hello文件,它就是一个可执行的目标文件。
ELF文件
参考文章ELF文件 - CTF wiki
参考文章[计算机那些事(4)——ELF文件结构]
在当前阶段,不需要对ELF文件有过深入的了解,只需要了解ELF文件内部的基本结构即可
ELF (Executable and Linkable Format)文件,也就是在 Linux 中的目标文件,主要有以下三种类型
- 可重定位文件(Relocatable File),包含由编译器生成的代码以及数据。链接器会将它与其它目标文件链接起来从而创建可执行文件或者共享目标文件。在 Linux 系统中,这种文件的后缀一般为
.o。 - 可执行文件(Executable File),就是我们通常在 Linux 中执行的程序。
- 共享目标文件(Shared Object File),包含代码和数据,这种文件是我们所称的库文件,一般以
.so结尾。一般情况下,它有以下两种使用情景:- 链接器(Link eDitor, ld)可能会处理它和其它可重定位文件以及共享目标文件,生成另外一个目标文件。
- 动态链接器(Dynamic Linker)将它与可执行文件以及其它共享目标组合在一起生成进程镜像。
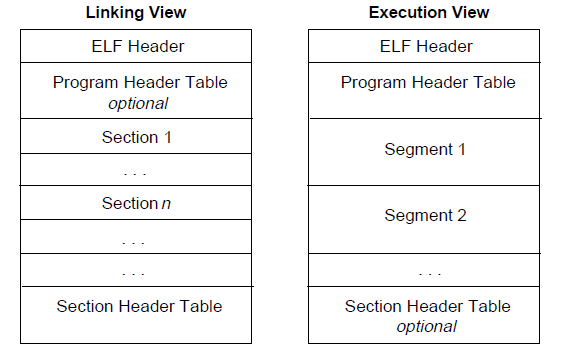
首先,我们来关注一下链接视图。
文件开始处是 ELF 头部( ELF Header),它给出了整个文件的组织情况。
如果程序头部表(Program Header Table)存在的话,它会告诉系统如何创建进程。用于生成进程的目标文件必须具有程序头部表,但是重定位文件不需要这个表。
节区部分包含在链接视图中要使用的大部分信息:指令、数据、符号表、重定位信息等等。
节区头部表(Section Header Table)包含了描述文件节区的信息,每个节区在表中都有一个表项,会给出节区名称、节区大小等信息。用于链接的目标文件必须有节区头部表,其它目标文件则无所谓,可以有,也可以没有。
这里给出一个关于链接视图比较形象的展示

对于执行视图来说,其主要的不同点在于没有了 section,而有了多个 segment。其实这里的 segment 大都是来源于链接视图中的 section。
注意:
1尽管图中是按照 ELF 头,程序头部表,节区,节区头部表的顺序排列的。但实际上除了 ELF 头部表以外,其它部分都没有严格的顺序。段(Segment)与节(Section)的区别。很多地方对两者有所混淆。段是程序执行的必要组成,当多个目标文件链接成一个可执行文件时,会将相同权限的节合并到一个段中。相比而言,节的粒度更小。
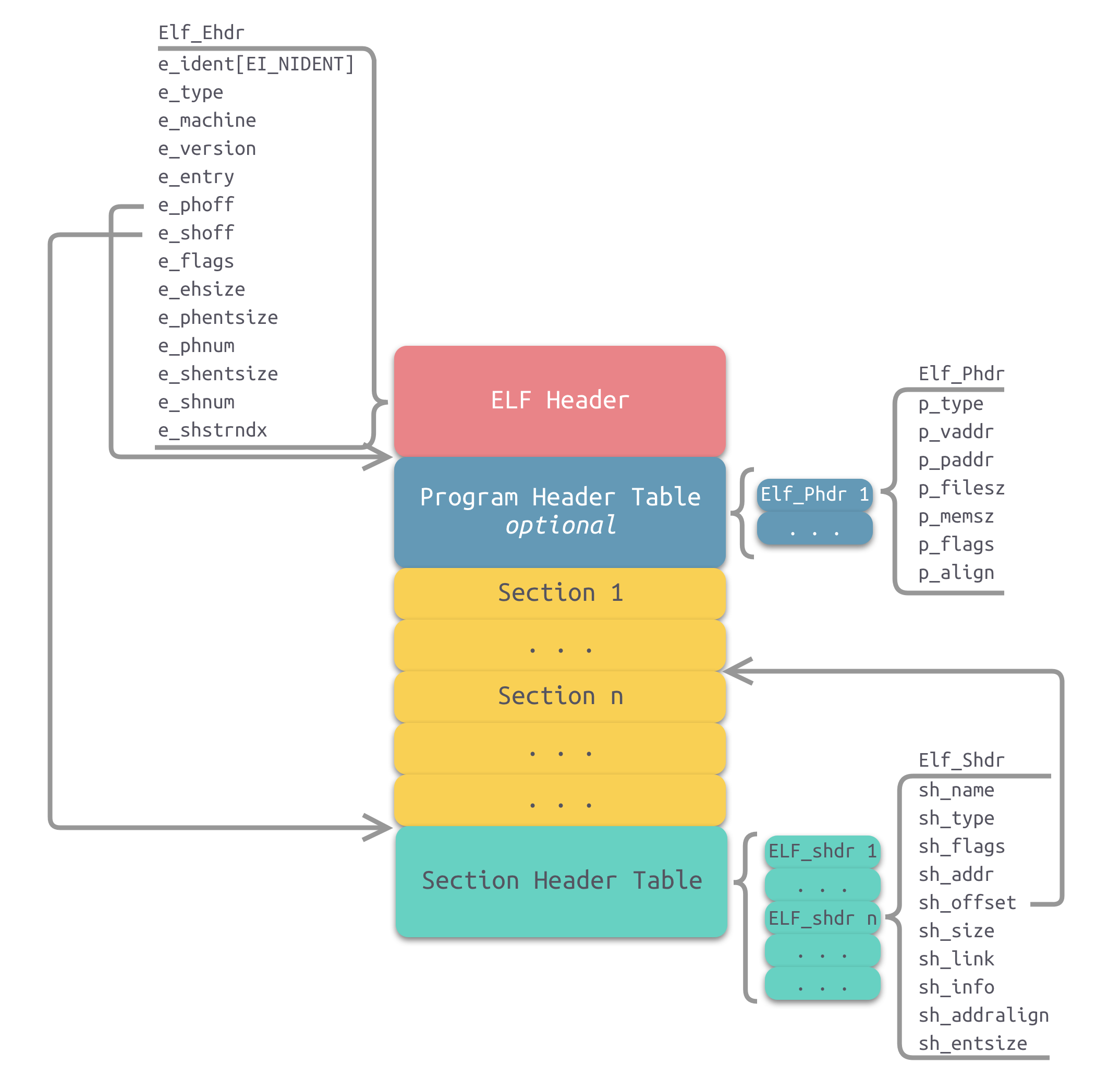
大家可以去上方的两篇文章好好看看,虽然可能看不懂,但还是需要初步了解,ELF文件在pwn中还是很重要的,pwn的第一步就是分析ELF文件
下面介绍ELF文件中出现及利用率极高的几个节
.text节
.text节是保存了程序代码指令的代码节。一段可执行程序,如果存在Phdr,则.text节就会存在于text段中。由于.text节保存了程序代码,所以节类型为SHT_PROGBITS。
.rodata节
rodata节保存了只读的数据,如一行C语言代码中的字符串。由于.rodata节是只读的,所以只能存在于一个可执行文件的只读段中。因此,只能在text段(不是data段)中找到.rodata节。由于.rodata节是只读的,所以节类型为SHT_PROGBITS。
.data节
.data节存在于data段中,其保存了初始化的全局变量等数据。由于.data节保存了程序的变量数据,所以节类型为SHT_PROGBITS。
.bss节
.bss节存在于data段中,占用空间不超过4字节,仅表示这个节本省的空间。.bss节保存了未进行初始化的全局数据。程序加载时数据被初始化为0,在程序执行期间可以进行赋值。由于.bss节未保存实际的数据,所以节类型为SHT_NOBITS。
.plt节(过程链接表)
.plt节也称为过程链接表(Procedure Linkage Table),其包含了动态链接器调用从共享库导入的函数所必需的相关代码。由于.plt节保存了代码,所以节类型为SHT_PROGBITS。
.got.plt节(全局偏移表-过程链接表)
.got节保存了全局偏移表。.got节和.plt节一起提供了对导入的共享库函数的访问入口,由动态链接器在运行时进行修改。由于.got.plt节与程序执行有关,所以节类型为SHT_PROGBITS。
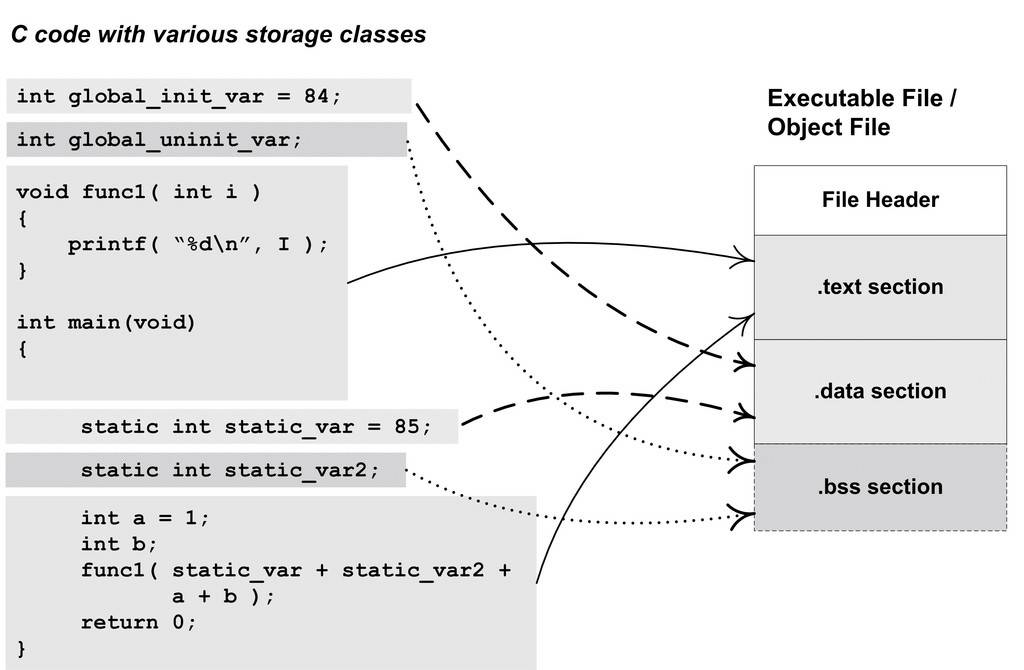
局部变量是存放在进程地址空间中的栈里,例如上文的a,在之后的利用之中,我们也会通过修改栈上的局部变量来达到部分目的.
操作系统
内存地址和内存空间
一个内存地址代表一个字节(8bit)的存储空间。一个字节是8bit,可以用八个二进制数来表示,如果四个一组,每一组正好对应一个十六进制数,那就是可以用两个十六进制数来表示一个字节,在我们使用IDA和GDB时,基本上都是和十六进制数打交道.
字节序,又称端序或尾序(英语中用单词:Endianness 表示),在计算机领域中,指电脑内存中或在数字通信链路中,占用多个字节的数据的字节排列顺序。
字节的排列方式有两个通用规则:
大端序(Big-Endian)将数据的低位字节存放在内存的高位地址,高位字节存放在低位地址。这种排列方式与数据用字节表示时的书写顺序一致,符合人类的阅读习惯。
小端序(Little-Endian),将一个多位数的低位放在较小的地址处,高位放在较大的地址处,则称小端序。小端序与人类的阅读习惯相反,但更符合计算机读取内存的方式,因为CPU读取内存中的数据时,是从低地址向高地址方向进行读取的。
例如如显示在起始位置为0x400001的位置上存储着0x12345678这一串数据,表示着:
| 端序 | 0x400001 | 0x400002 | 0x400003 | 0x400004 |
|---|---|---|---|---|
| 小端序 | 0x78 | 0x56 | 0x34 | 0x12 |
| 大端序 | 0x12 | 0x34 | 0x56 | 0x78 |
在题目中,小端序采用较多
虚拟内存与物理内存
参考文章一步一图带你构建 Linux 页表体系 —— 详解虚拟内存如何与物理内存进行映射
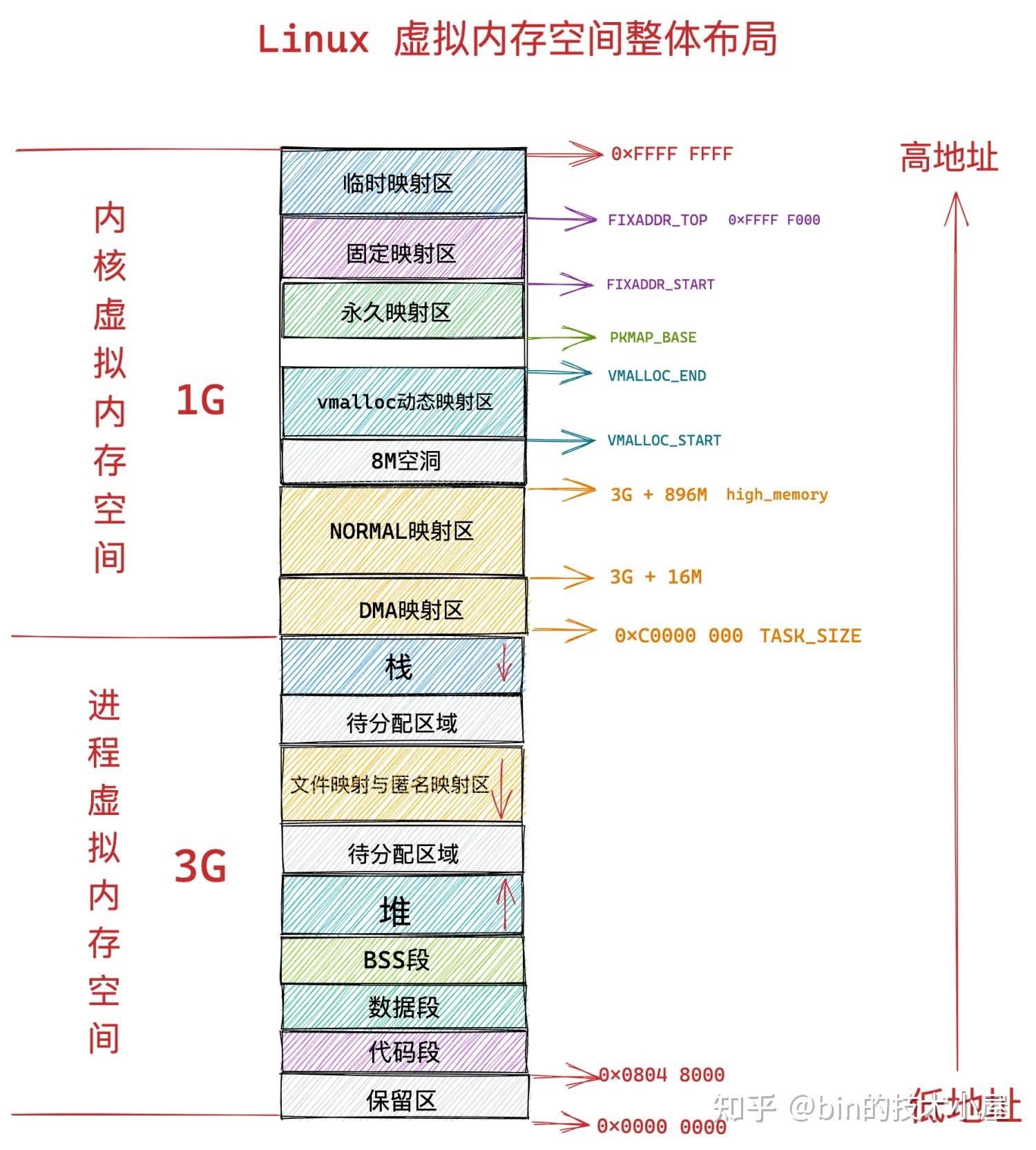
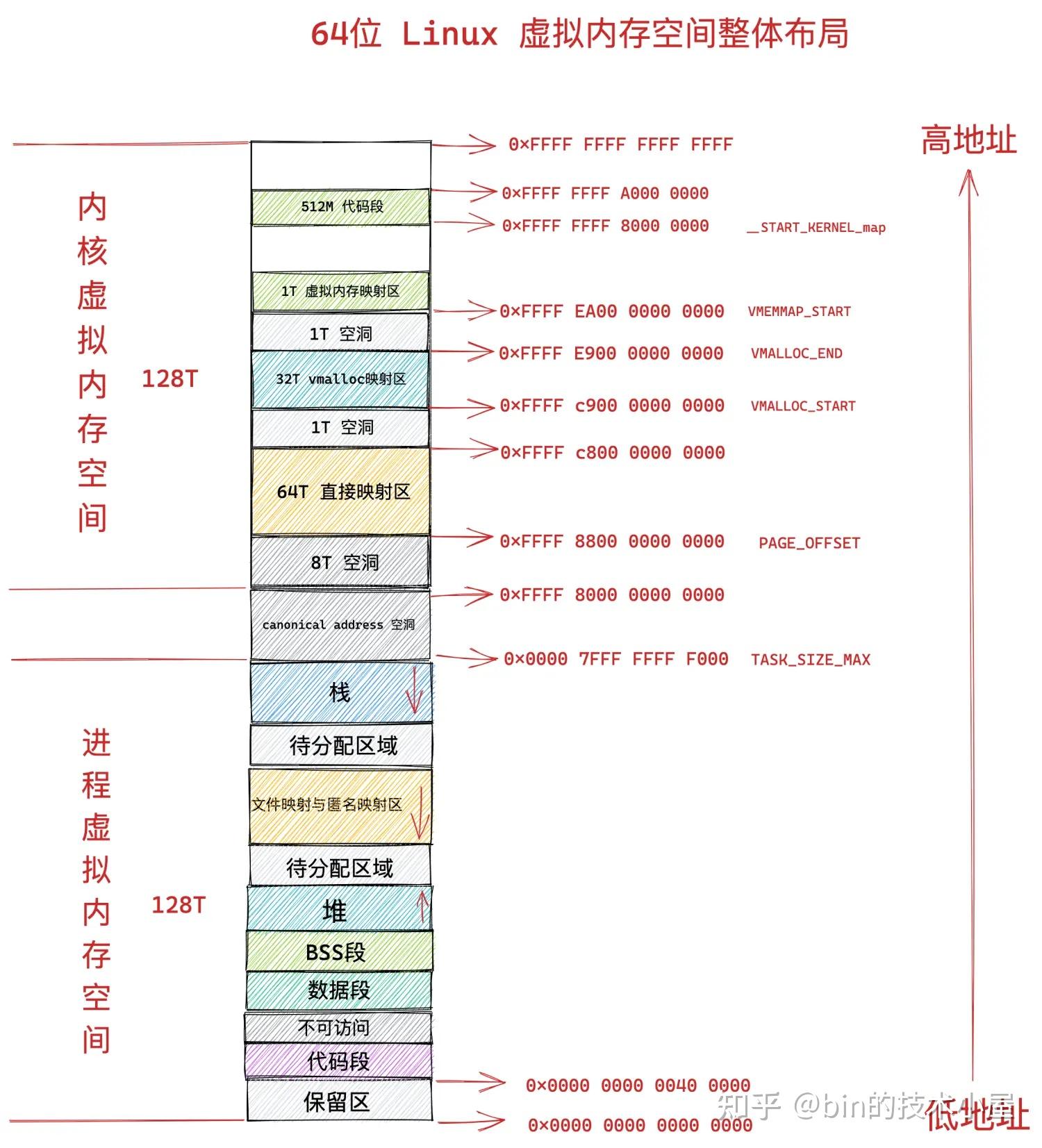
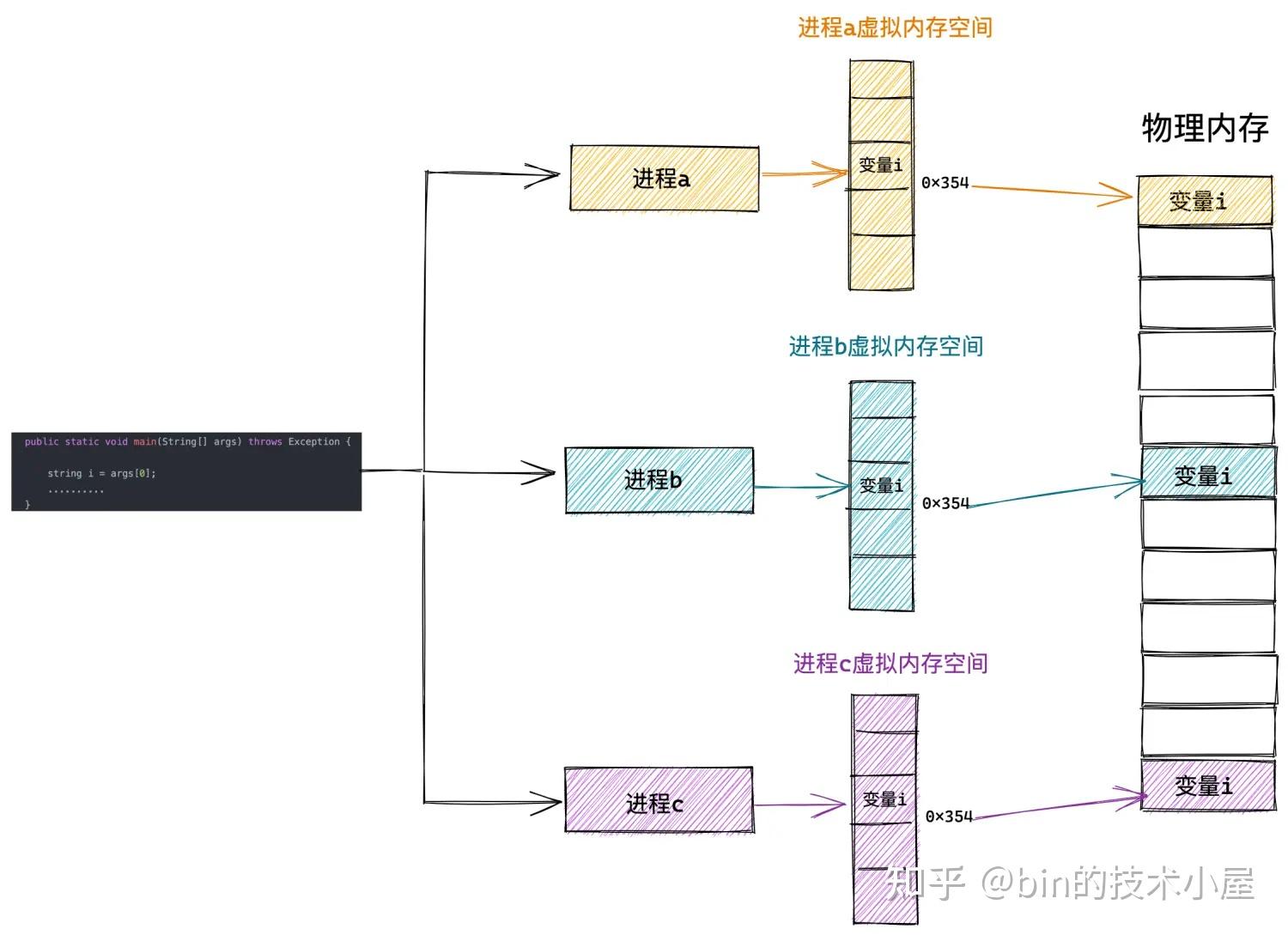
操作系统为每个进程营造出一片独立的虚拟地址空间,使得进程与进程之间相互隔离,互不干扰的,解决了多进程同时运行时产生的内存地址冲突问题。
同时虚拟内存还提供了系统安全方面的保障,会对进程访问内存的行为进行相关的安全权限检查,保障了系统的稳定性和安全性。比如:
- 有些物理内存页只允许内核来访问,进程在用户态的时候是无法访问的。
- 虚拟内存中保存了访问其映射的物理内存相关的权限,进程只能执行规定权限范围内的访存操作。比如,上面虚拟内存空间里代码段的权限是可读,可执行,但是不可写。数据段具有可读可写的权限但是不可执行。堆则具有可读可写,可执行的权限,栈一般是可读可写的权限,一般很少有可执行权限。而文件映射与匿名映射区存放了共享链接库,所以也需要可执行的权限。